Avoltech's Website
Speech Sentiment Analysis Using Acoustic Features
As technology has developed so has our methods of interacting with them. From physical keys, to virtual Graphical User Interfaces, and finally to Voice User Interfaces, Human Computer Interaction has come a long way. Today, we can successfully use are voice to give commands to different software. This is achieved by the use of Natural Language Processing, i.e., the linguistic aspect of voice interaction. In this project we try to understand if the acoustic approach can be used for a overall better voice interaction. Here, we use the sound waves from human voices to analysis the underlying tone of the speaker and classify it according to their emotion. This would help in providing additional information about the user, the state of his emotion at that moment. This sentiment detection is achieved using machine learning. The project consists of 2 important parts. The first step is extraction of features form the sound clips and the second one is to train a model based on the acquired feature matrix. Feature extraction step is carried out to improve model performance by taking out the import features and using them as inputs for model, rather than using the sound waves as input directly. A comparison between the features and the resultant accuracy is also carried out, along with the comparison of multiple features as input to the model instead of a single one.
Human–computer interaction (HCI) studies the design and use of computer technology, focused on the interfaces between people (users) and computers. Right from the start of emerging new technologies Graphical User Interfaces (GUIs) have been the industry standard for decades now. While GUI has virtual keys and buttons, a voice-user interface (VUI) makes spoken human interaction with computers possible, using speech recognition to understand spoken commands and answer questions, and typically respond with a text to speech module as a reply. This field has been mainly driven based upon the linguistic part of the speech. The new advancements in Voice Interaction has been made mainly in the fields of Natural Language Processing, whereas the acoustic part of the speech, the underlying sentiment behind the speech hasn’t been explored much. Here in this project, we analysis the sentiment in the voice of the speaker. This is carried out using machine learning.
The challenging aspect of this idea is the feeding of data to the model. As sound waves are more or less set of random values, tweaking and shaping them into sensible features so as to feed them as input, is the core of this project. This feature extraction stage is carried out using the functions present in Librosa python package. This is a library focused on sound processing and provides useful algorithms for feature extractions. In this project we have used various sound processing and they are MFCC (Mel Frequency Cepstral Coefficients), Spectral Contrast, Chroma, Mel Spectrogram Frequency and Tonnetz. The datasets used in this project is the RAVDESS (Ryerson Audio Visual Database of Emotional Speech and Song) and CORPUS JL opensource datasets.
To read more about the methodoloy and procedure, please read the report linked at the end.
Results
Following tables contain the result obtained from the project, which includes performance of the model and the comparison between different feature extraction technique and thier combinations.
Table 1: Individual feature comparison table
|
Dataset Used |
Feature(s) |
Selection Type |
Test Score |
Train Score |
Average Score |
|
CORPUS JL |
chroma |
avg |
0.5469 |
0.6901 |
0.6185 |
|
minmaxavg |
0.5521 |
0.7201 |
0.6361 |
||
|
contrast |
avg |
0.6667 |
0.7747 |
0.7207 |
|
|
minmaxavg |
0.6667 |
0.7747 |
0.7207 |
||
|
mel |
avg |
0.8542 |
0.9362 |
0.8952 |
|
|
minmaxavg |
0.8385 |
0.9089 |
0.8737 |
||
|
mfcc |
avg |
0.8698 |
0.9219 |
0.8958 |
|
|
minmaxavg |
0.8802 |
0.9232 |
0.9017 |
||
|
tonnetz |
avg |
0.4323 |
0.6237 |
0.5280 |
|
|
minmaxavg |
0.3229 |
0.5951 |
0.4590 |
||
|
RAVDESS |
chroma |
avg |
0.3556 |
0.6164 |
0.4860 |
|
minmaxavg |
0.3556 |
0.6462 |
0.5009 |
||
|
contrast |
avg |
0.5259 |
0.6611 |
0.5935 |
|
|
minmaxavg |
0.5259 |
0.6611 |
0.5935 |
||
|
mel |
avg |
0.5259 |
0.7430 |
0.6345 |
|
|
minmaxavg |
0.5556 |
0.6890 |
0.6223 |
||
|
mfcc |
avg |
0.6741 |
0.8343 |
0.7542 |
|
|
minmaxavg |
0.6667 |
0.8287 |
0.7477 |
||
|
tonnetz |
avg |
0.3556 |
0.5885 |
0.4720 |
|
|
minmaxavg |
0.2741 |
0.5512 |
0.4126 |
Table 2: Combination of feature extraction technique comparison
|
Dataset Used |
Feature(s) |
Selection Type |
Test Score |
Train Score |
Average Score |
|
CORPUS JL |
contrast,mel |
avg |
0.547 |
0.690 |
0.8880 |
|
minmaxavg |
0.552 |
0.720 |
0.8770 |
||
|
mffcc, contrast |
avg |
0.667 |
0.775 |
0.8926 |
|
|
minmaxavg |
0.667 |
0.775 |
0.9010 |
||
|
mfcc, mel |
avg |
0.854 |
0.936 |
0.9010 |
|
|
minmaxavg |
0.839 |
0.909 |
0.9121 |
||
|
mfcc, contrast, mel |
avg |
0.870 |
0.922 |
0.8971 |
|
|
minmaxavg |
0.880 |
0.923 |
0.9128 |
||
|
RAVDESS |
contrast, mel |
avg |
0.356 |
0.616 |
0.6817 |
|
minmaxavg |
0.356 |
0.646 |
0.6316 |
||
|
mfcc, contrast |
avg |
0.526 |
0.661 |
0.7644 |
|
|
minmaxavg |
0.526 |
0.661 |
0.7356 |
||
|
mfcc, mel |
avg |
0.526 |
0.743 |
0.7644 |
|
|
minmaxavg |
0.556 |
0.689 |
0.7598 |
||
|
mfcc, contrast, mel |
avg |
0.674 |
0.834 |
0.7644 |
|
|
minmaxavg |
0.667 |
0.829 |
0.7598 |
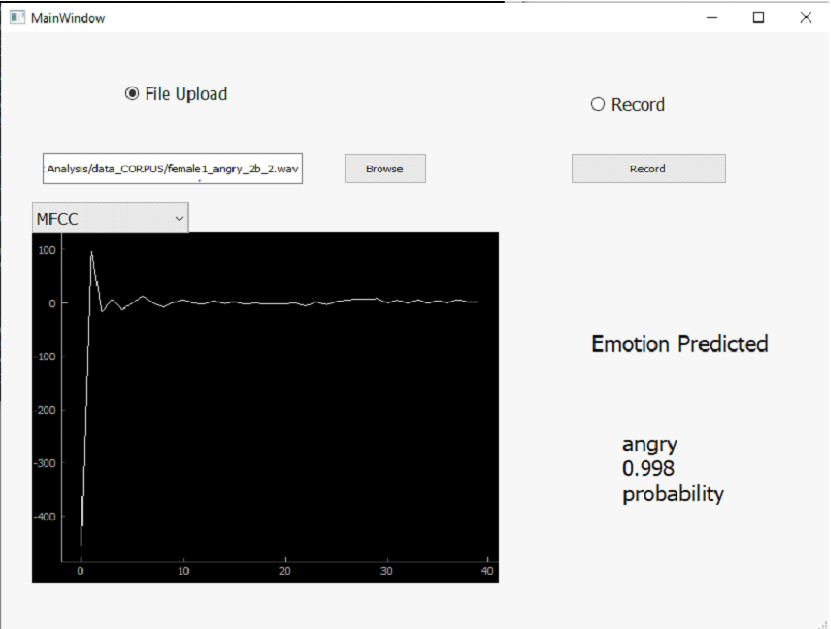
An application was also built that was use to classify the emotion in real time. PyQt5 was used to build the GUI of the application.
Conclusion
Using just the intensity and the variance of the sound waves in a human speech, the underlying emotions can be understood to some extent without linguistic processing. This means that acoustic features can act as an important factor in Speech Emotion Recognition (SER) with its big brother Natural Language Processing (NLP). Even without knowing the actual words the sound waves can be analyzed to understand the emotion, this result can further be developed by classifying the words in the speech based on their sentiments, positive and negative. This combination would yield much more better results. MFCC still stands out to be the best feature extraction technique for speech sentiment analysis for short duration sound clips. A combination of the feature extraction techniques or the minimum and the maximum values of the features does not provide a substantial increase in the accuracy than a single technique alone.
The entire report can be found here.
The published paper can be found on this link: https://ijisrt.com/feature-extraction-techniques-comparison-for-emotion-recognition-using-acoustic-features